UNaR
An uncertainty-regularized offline RL project that turns critic disagreement into adaptive behavior regularization for TD3+BC.
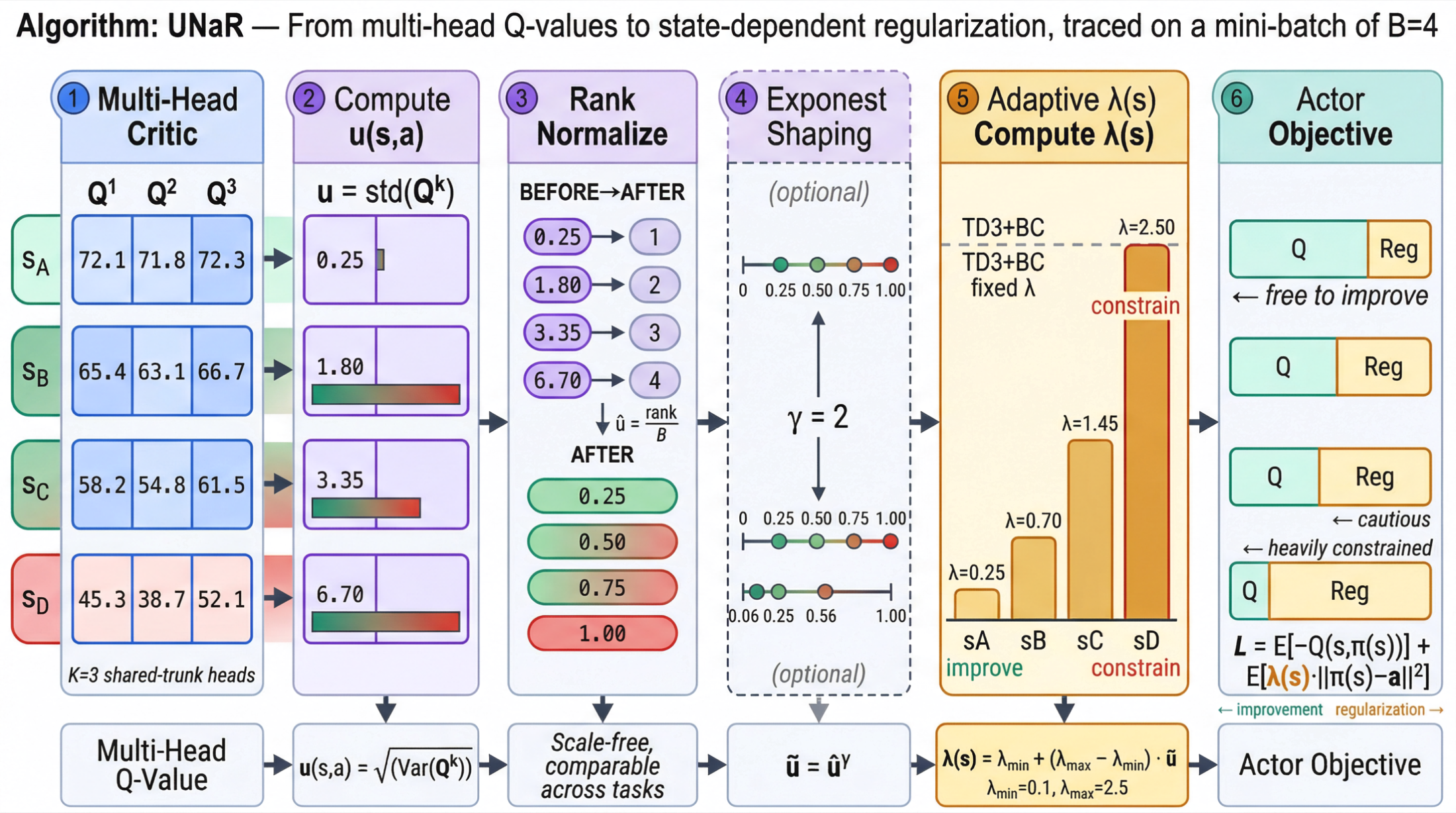
UNaR is an uncertainty-regularized offline reinforcement learning project built around a minimal extension of TD3+BC. The main goal is to replace fixed global behavior regularization with a state-dependent uncertainty-aware control signal, so the policy can stay conservative in risky regions while still improving where the critic is confident.
Overview
Offline reinforcement learning learns a policy only from a fixed dataset, without further interaction with the environment. The central difficulty is the trade-off between policy improvement and distributional safety:
- moving away from the behavior policy may improve return
- but drifting into out-of-distribution regions can trigger severe overestimation and performance collapse
Strong baselines such as TD3+BC and IQL address this through behavior regularization, but typically with a fixed or globally tuned coefficient. UNaR is built on the observation that the risk of deviation is not uniform. It is fundamentally state-action dependent.
Core Idea
UNaR stands for Uncertainty-Normalized Behavior Regularization. The core idea is simple:
- if a state-action region has high uncertainty, the policy should stay closer to the dataset
- if the uncertainty is low, the policy can be allowed to deviate more aggressively for improvement
Instead of using one global regularization coefficient, UNaR introduces a state-dependent regularization schedule driven by critic uncertainty.
Uncertainty Estimation
UNaR uses a lightweight multi-head critic. Let (Q_{\psi}^{(k)}(s,a)), (k = 1, \dots, K), denote (K) heads that share a common feature trunk.
The mean prediction is
\[\mu_Q(s,a) = \frac{1}{K} \sum_{k=1}^{K} Q_{\psi}^{(k)}(s,a).\]The disagreement variance is
\[\sigma_Q^2(s,a) = \frac{1}{K} \sum_{k=1}^{K} \left(Q_{\psi}^{(k)}(s,a) - \mu_Q(s,a)\right)^2.\]UNaR defines the uncertainty score as
\[u(s,a) = \sqrt{\sigma_Q^2(s,a)}.\]This gives a cheap approximation of epistemic uncertainty while remaining practical in single-GPU training settings.
Uncertainty Normalization
Raw disagreement values are not directly comparable across different tasks or even across batches. UNaR therefore applies batch-wise normalization.
The default implementation uses rank-based normalization:
\[\hat{u}(s,a) = \frac{\mathrm{rank}(u(s,a))}{B},\]where (B) is the batch size.
To further amplify contrast when desired, UNaR applies an optional shaping exponent:
\[\tilde{u}(s,a) = \hat{u}(s,a)^\gamma,\]with (\gamma \ge 1).
This keeps the uncertainty signal stable and interpretable without introducing a heavy calibration procedure.
UNaR on Top of TD3+BC
UNaR is instantiated as a simple extension of TD3+BC.
The standard TD3+BC actor objective is
\[\mathcal{L}_{\pi} = -\mathbb{E}_{s}\left[Q(s,\pi(s))\right] + \lambda \cdot \mathbb{E}_{(s,a)\sim\mathcal{D}} \left[\lVert \pi(s) - a \rVert_2^2\right].\]UNaR replaces the global coefficient (\lambda) with a state-dependent coefficient:
\[\lambda(s) = \lambda_{\min} + \left(\lambda_{\max} - \lambda_{\min}\right)\cdot\tilde{u}(s,\pi(s)).\]The resulting actor objective becomes
\[\mathcal{L}_{\pi}^{\text{UNaR}} = \mathbb{E}_{s}\left[-Q(s,\pi(s))\right] + \mathbb{E}_{(s,a)\sim\mathcal{D}} \left[ \lambda(s)\cdot \lVert \pi(s) - a \rVert_2^2 \right].\]This means the behavior-cloning penalty is no longer constant. It grows automatically in uncertain regions and relaxes in more trustworthy ones.
Interpretation
UNaR can be interpreted as a risk-aware policy constraint:
- high uncertainty leads to stronger conservatism
- low uncertainty allows more aggressive policy improvement
Conceptually, it approximates a robust objective of the form
\[\max_{\pi} \; \mathbb{E}[Q(s,\pi(s))] - \alpha \cdot \mathbb{E}[u(s,\pi(s))],\]without explicitly redesigning the critic loss itself.
Why It Is Interesting
UNaR is intentionally designed to be minimal:
- it uses a shared-trunk critic with only 3 heads
- it adds very limited overhead compared with standard TD3+BC
- it does not require large ensembles or heavyweight uncertainty models
- it drops into an existing TD3+BC workflow with only a compact actor-side modification
That combination of simplicity, interpretability, and robustness is the main reason this project is interesting.
Experimental Setup
UNaR is evaluated on the D4RL benchmark, focusing on standard MuJoCo continuous-control tasks:
HalfCheetahHopperWalker2d
Each environment is tested on:
medium-v2medium-replay-v2
The evaluation protocol uses:
- normalized D4RL score as the main metric
- 3 random seeds per configuration
- periodic deterministic-policy rollout evaluation
- final reporting as mean ± standard deviation across seeds
The main baselines are:
BCTD3+BC
Diagnostics
To verify that the mechanism behaves as intended, UNaR tracks several diagnostics beyond final score:
- the mean and distribution of (\lambda(s))
- Q uncertainty statistics
- policy deviation from dataset actions
In particular, the policy deviation term is monitored through
\[\lVert \pi(s) - a_{\text{data}} \rVert_2^2.\]These diagnostics help check whether UNaR is truly increasing regularization in uncertain regions and reducing it when the critic is more confident.
Key Takeaway
UNaR provides a minimal but meaningful upgrade to offline RL:
It replaces a fixed global behavior constraint with a data-dependent, uncertainty-aware regularization mechanism.
The result is a method that aims to improve robustness while preserving the compactness and practicality of the underlying TD3+BC framework.
Links
- Repository: ShuhongDai/UNaR
- README: Method overview and quick start